PostgreSQL 17 was recently released and one of the main points of emphasis is performance improvement.
Below, I’ve cherry picked a few of the performance enhancing features they mention in the official release post which may improve PostgreSQL’s performance in our Reserva database benchmark:
- The vacuum process was given a new internal structure to consume less memory and CPU resources.
- This is important because PostgreSQL tends to be CPU constrained when being benchmarked by Reserva.
- The WAL writer has been improved, and they claim that high concurrency workloads may see as much as a 2X improvement in write throughput.
- This is important because I increase concurrency until payments per second stops improving when running Reserva.
- The performance of B-tree indexes have been improved when they are being queried using an
INclause.- This is important because on of the two main update/write actions performed by Reserva, looking up accounts, uses an
INclause on a B-tree index.
- This is important because on of the two main update/write actions performed by Reserva, looking up accounts, uses an
There are other improvements listed in that article, but those are the ones that caught my eye.
Benchmark setup
Let’s talk about the hardware, database versions, and configurations that were used to conduct this test.
Hardware
I ran these benchmarks on lil-bit and speedy-1.
Databases
Now, let’s discuss the databases used and how they were configured.
Versions
Both of the database versions were deployed using the official PostgreSQL docker images. The specific Docker images tested were:
postgres:17.0-bookwormpostgres:16.4-bookworm
Both databases were deployed with identical commands, on the same computer.
Config
I’ve spent a lot of time configuring PostgreSQL performance parameters and the only one I’ve found that makes a significant difference in the Reserva benchmark is shared_buffers.
The PostgreSQL docs recommend a value of around 25% of total system RAM for shared_buffers, so I used the following minimal postgresql.conf file:
listen_addresses = '*'
shared_buffers = 16GB
shared_buffers = 16GBPopulating data
For each database, I ran a DB preparation SQL scripts to create:
- 100 banks with access to the payments system and corresponding users + permissions + auth tokens.
- 10,000,000 accounts, each with a corresponding payment card.
You can see the SQL setup scripts, along with the rest of the code, on Reserva’s Github page.
The test
I ran Reserva with the following settings for both databases:
- 64 concurrent requests at a time
- Maximum of 64 open database connections (idle or active)
- 1 hour duration
- Deletes enabled as part of the workflow
Aggregation query
At the end of the test, I executed the following query to show how many payments were made over the course of the hour. The results of those queries are visualized below.
SELECT
DATE_TRUNC('minute', CREATED_AT) AS MINUTE,
COUNT(*) AS NUMBER_OF_TRANSFERS
FROM
TRANSFERS
GROUP BY
MINUTE
ORDER BY
MINUTE;Results
Here are how many payments Reserva processed per minute over the course of the hour:
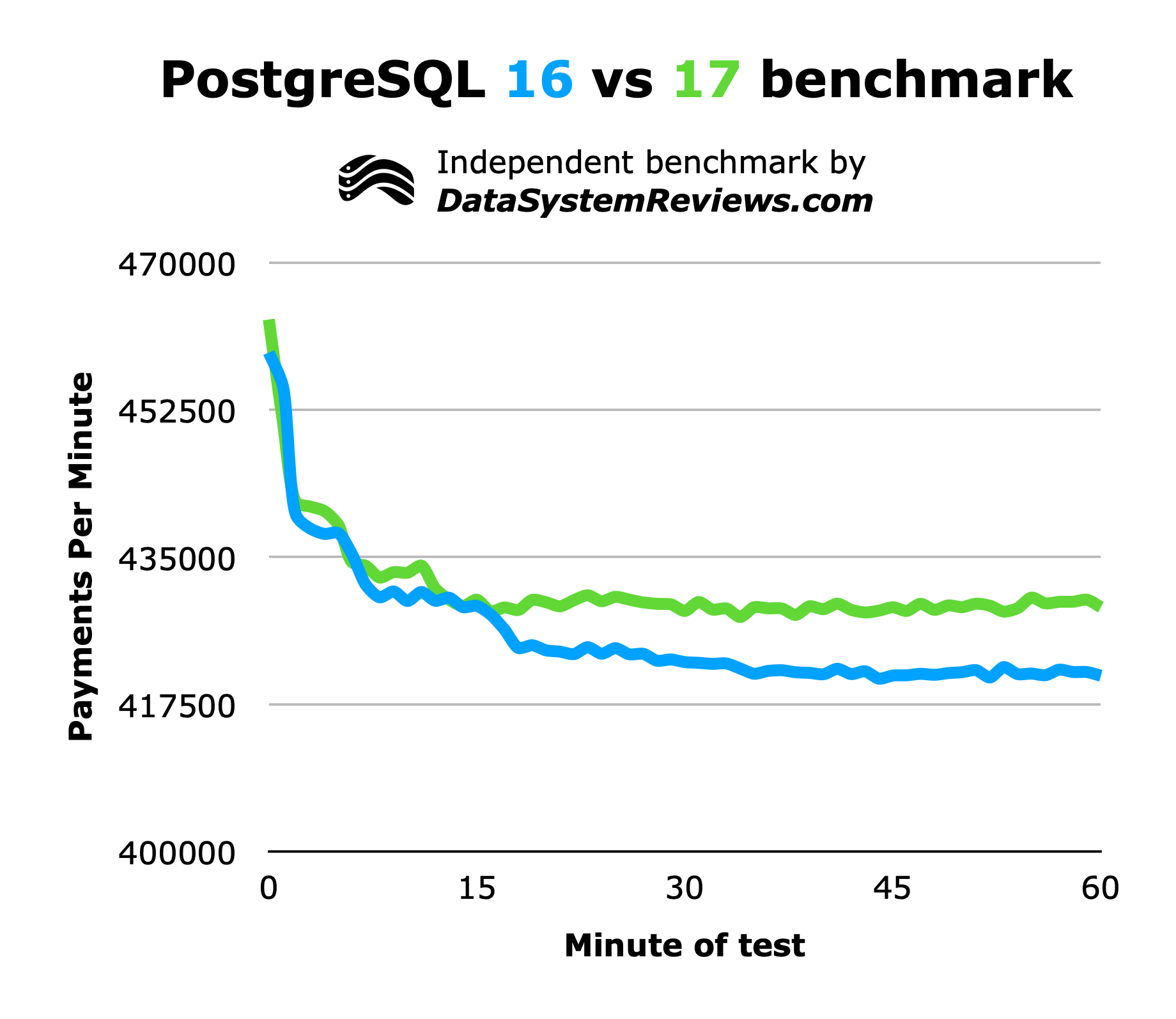
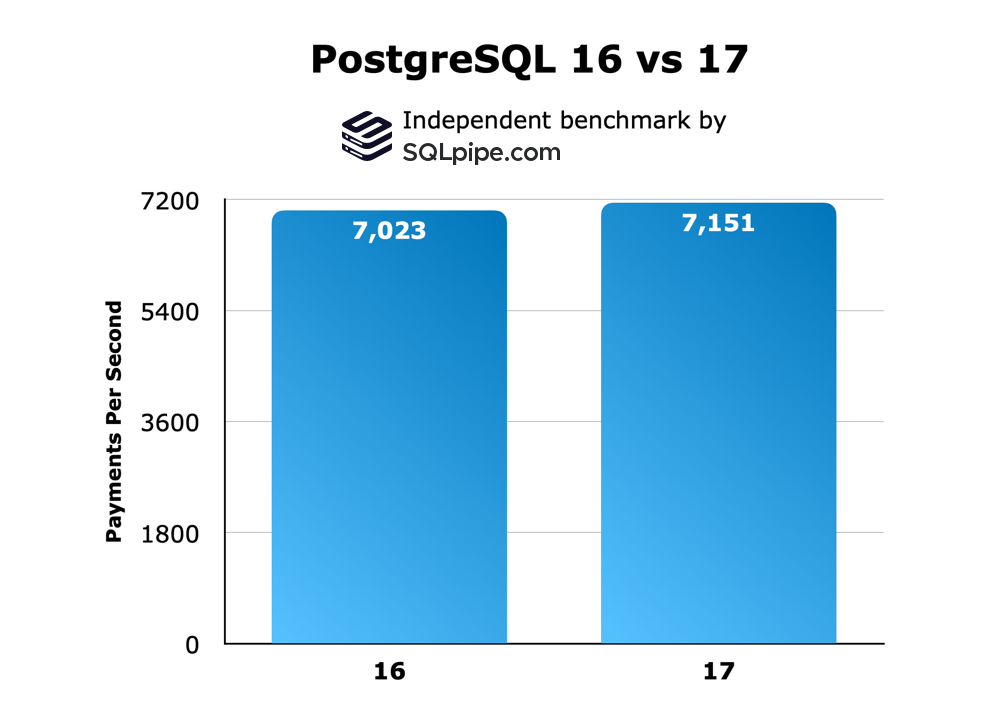
PostgreSQL 17 was a bit faster than 16 - a consistent 2% faster after the performance of both systems plateaued. Here is that same data, but visualized in a different way. I summed how many payments were made over the last 30 minutes of each test (so, after the plateau was reached) and divided that number by how many seconds are in 30 minutes
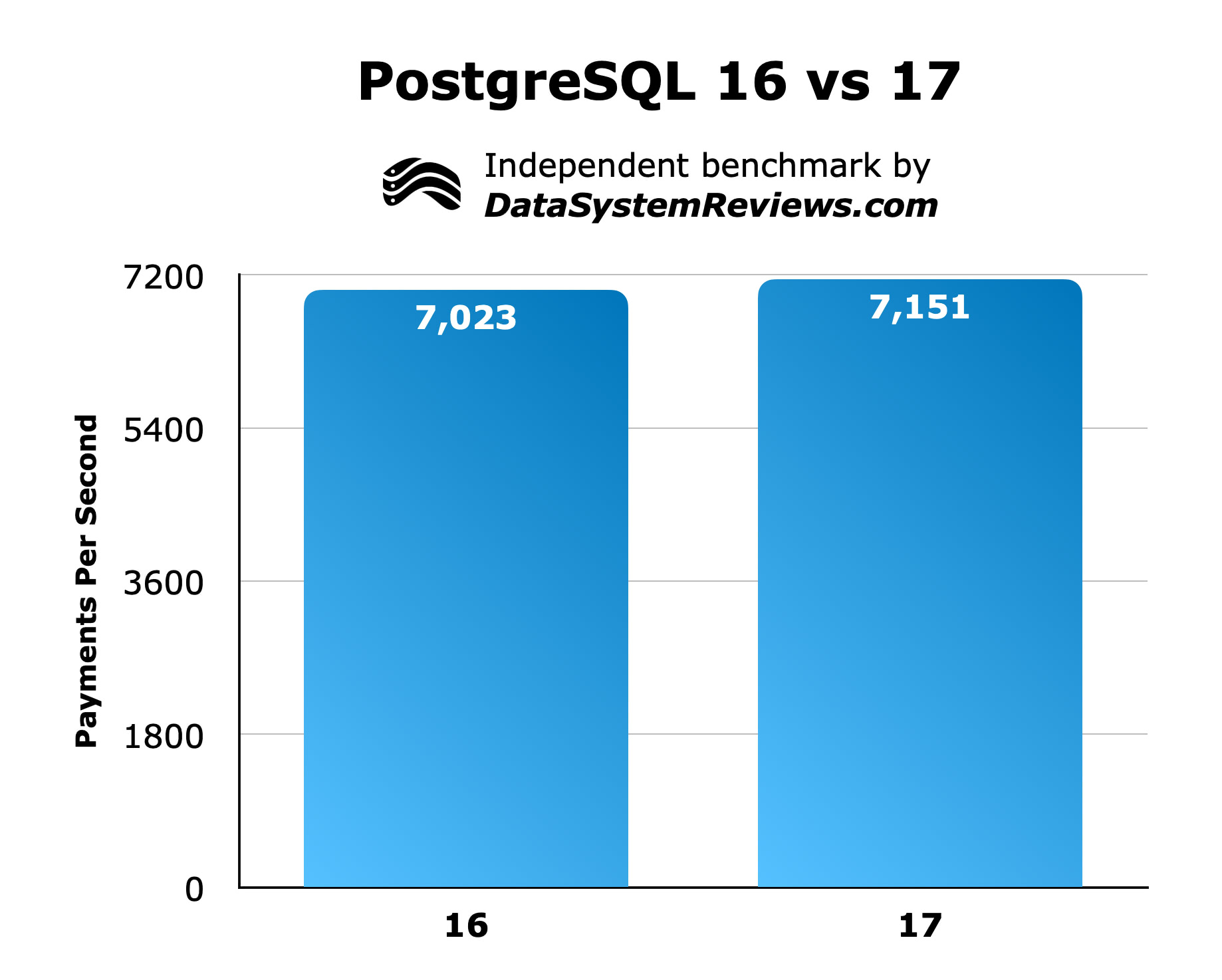
A 2% speed increase isn’t anything to write home about, but PostgreSQL is so well-optimized already that any measurable gains is a bonus.
Reserva pinned the CPU of the database server to 100% on all cores during the entirety of the test, so it is likely that whatever gains we are seeing is coming from some processing algorithm improvement, not an I/O one. Maybe we would see more improvement if my test setup had a faster CPU, but realistically speaking, a well-powered, well-cooled machine with 8 vCPUs is representative of what a lot of orgs will be using in the cloud for a production workload, anyways.
Conclusion
PostgreSQL 17 is 2% faster than PostgreSQL 16 in my benchmarks. In my opinion, this performance benefit is not worth migrating from 16 to 17 on its own. However, there are many other features, such as failover control during logical replication, which may be worth switching for.
Overall, PostgreSQL 17 is another solid release from the PostgreSQL Global Development Group. The system is already the fastest open-source database in my tests, and this version is faster than the last.