SQLpipe is a data consultancy that charges based on how much we can save on your existing pipelines. So, we’re very interested in how much we can save on data pipelines.
This case study investigates how much it would cost to ingest data from the Bank for International Settlements (BIS). These datasets contain information that many financial institutions use to develop economic models, and can be found on the BIS data portal.
The savings
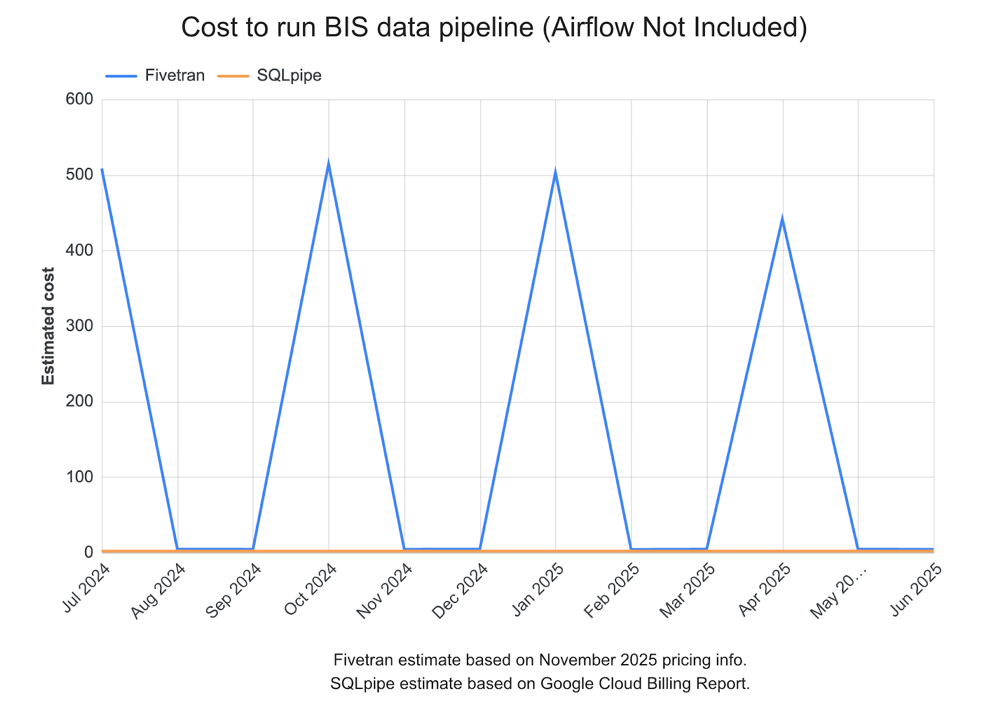
This data pipeline saves about 99% on downloading and processing data from the BIS, as compared to using Fivetran. Below is a live chart showing estimated spend by month.
Yearly totals are around $2,000 for Fivetran, and $24 for my data pipeline. Fivetran’s cost is spiky because many of the BIS releases are quarterly, and they charge per monthly active row, or “MAR”.
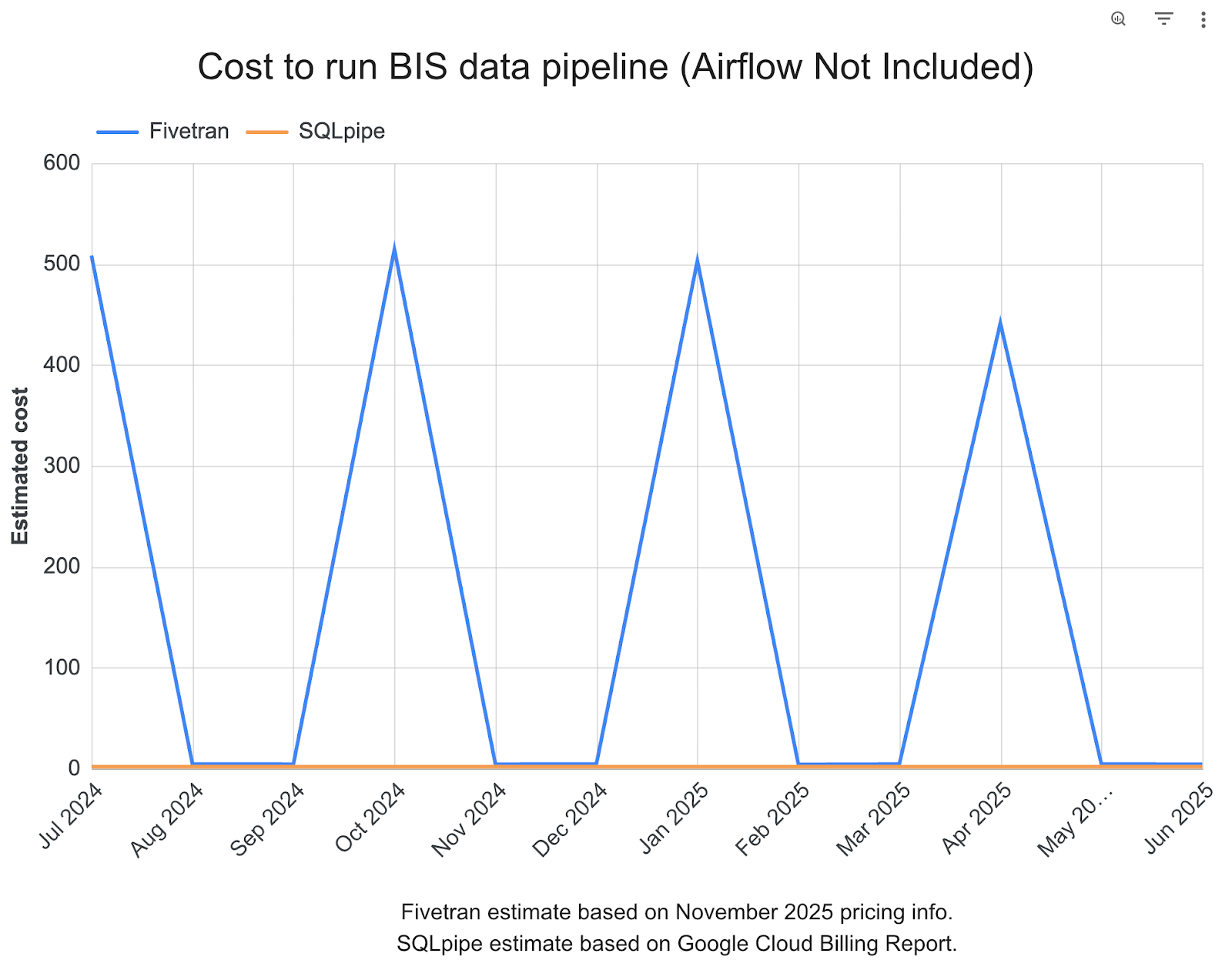
If you include the resources that are used to host Airflow, my pipeline only saves about 30% as compared to Fivetran. However, that Airflow instance can (and will) be used to orchestrate other data pipelines, so I find it fair to exclude it from my calculations.
In the spirit of transparency, below is another comparison chart, including Airflow costs. Yearly costs are still $2,000 for Fivetran, and $1,400 for my pipeline.

My pipeline
I need to download, unzip, clean, and upload data into Bigquery from BIS data. To do this, I wrote an Airflow DAG which stitches together some Google Cloud Operators with data movement tools written in Golang. Generally speaking, the heavy lifting is done by the data tools, running as Google Cloud Run jobs.
The pipeline, as visualized by Airflow, looks like this, and runs nightly:

Let’s zoom in on a few different parts to show what’s really going on.
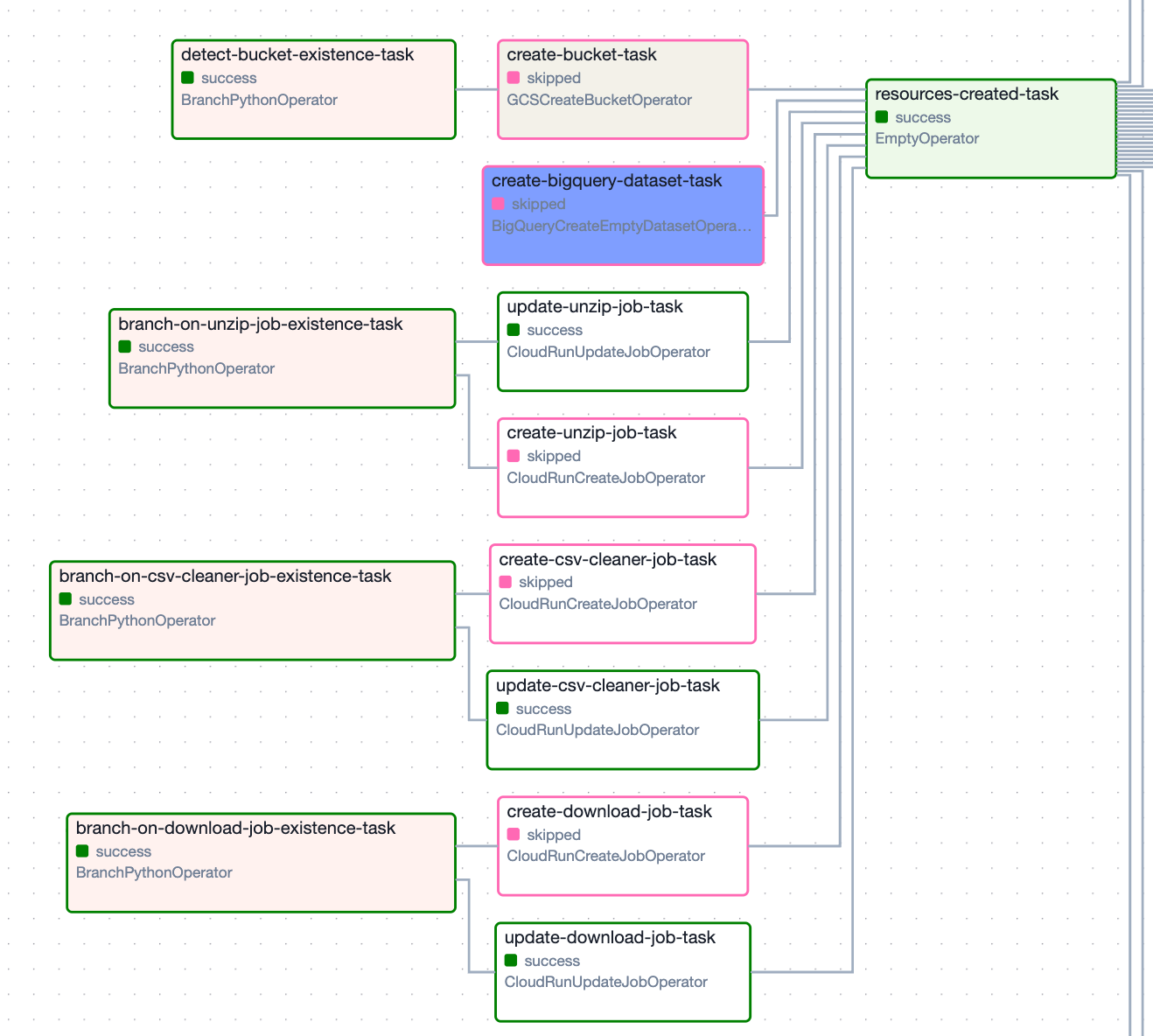
First step: Ensure cloud resources are available
This pipeline is hosted on GCP. Before we move any data, we need to ensure that there is a GCS bucket and BigQuery dataset to receive the data. Also, I ensure that the Cloud Run jobs I’ll use to download and process the data are created (and updated to the latest version).
All of these checks happen in parallel, and cost nothing. They take a few seconds.
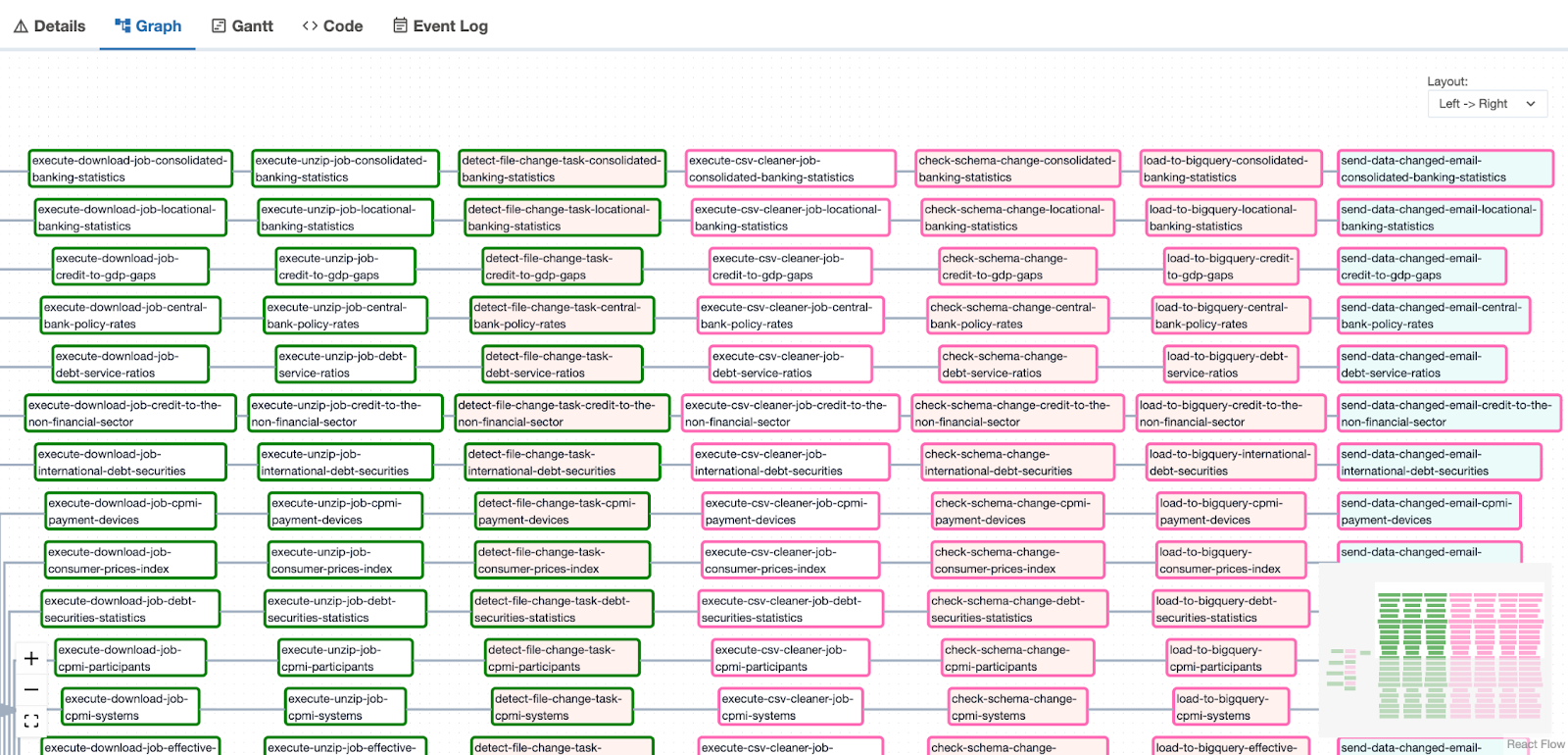
Second step: Move the data
Once we ensure the cloud resources are there, we perform the following steps, in parallel, for the 23 datasets that the BIS currently publishes:
- Execute a GCP Cloud Run job to download a zip file from the BIS, using my download file to GCS data tool. This task is limited to a concurrency pool of 2, to be polite to the people running the BIS’ IT systems.
- Execute a GCP cloud run job to unzip that file, using my unzip file in GCS data tool.
- Check if the latest data is different from the data we already have, using the built in hash from the GCS bucket. If it’s not different, we skip the rest of the steps for that particular dataset. This happens most nights, as the data changes infrequently. Skipped tasks are colored pink.
- If the data changed, we execute a GCP cloud run job to clean the CSV, using my CSV cleaner data tool. It chucks some NaNs, cleans up the column names, etc.
- We check if the schema has changed since the last data load. If it has, we error and email ourselves, as there are dependencies downstream of this pipeline that would break, if the schema changed.
- We then load the cleaned data into BigQuery.
- Last, if the data changed, we email ourselves to see if there’s anything interesting in there to write a blog post about!
What does this pipeline cost to operate?
Basically nothing, if you don’t include the Airflow costs. Here is a screenshot of a single day’s usage, in my GCP billing report:
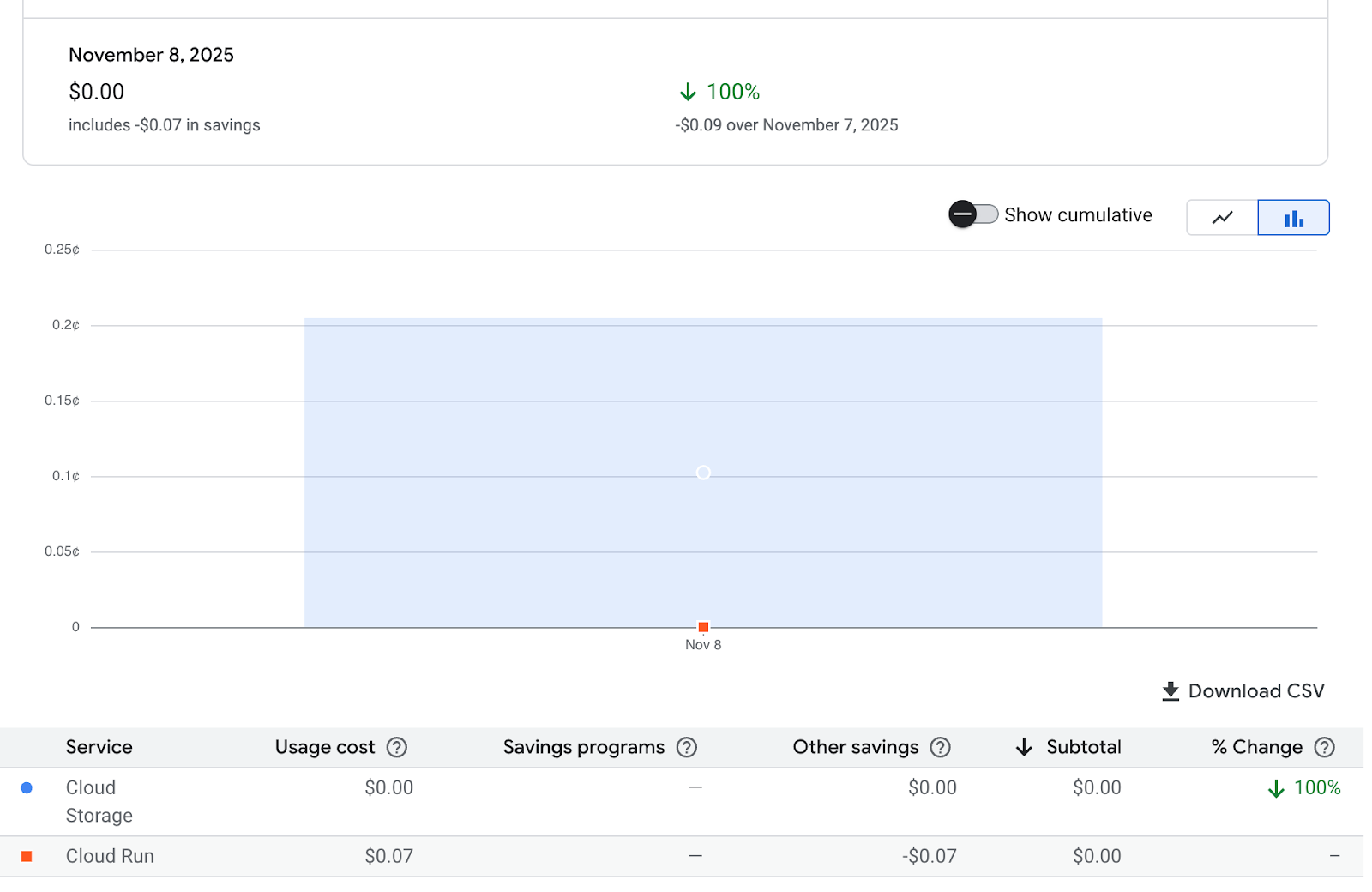
In fact, my usage is still below the “free tier” threshold, so I will literally pay nothing. For the rest of the article, I’ll assume this pipeline costs around $2 per month to run, which I think is a realistic expectation. If that number changes in the next few months, I’ll update the article.
How much did this pipeline cost to develop?
SQLpipe is a data consultancy that charges based on how much we can save on your existing pipelines. So, it’s hard to give a direct comp.
However, I estimate it would cost about $3,000 for a data engineering team to develop this pipeline.
Let’s assume a typical data engineer earns $120,000 per year, which comes out to around $75 an hour after benefits, taxes, etc.
It took me 4 working days to build this pipeline, which at $75 an hour, comes out to $2400. I’m a single dev without coordination overhead (PR reviews, meetings, project managers, etc), so let’s just say it would take a week at a typical company. This comes out to $3,000.
Fivetran
Fivetran supports the ability to ingest a CSV. Let’s give them the benefit of the doubt on a few items:
- Assume the CSVs are magically placed in a GCS bucket, for free, with no data or orchestration costs.
- Assume that Fivetran’s data cleaning tools are robust enough to handle the BIS’ dirty data. It has commas in the CSV headers. Tsk-tsk!
- Assume that Fivetran’s incremental syncing works flawlessly on flat files without a proper primary key (these files do not have a PK).
I am skeptical of item #1. You’re probably going to want some professional orchestration (such as Airflow) to download the file, retry and alert on failures, etc. I would hope that Fivetran, who is a market leader, has items #2 and #3 sorted.
How much would this pipeline cost to run on Fivetran?
I estimate around $2,000 a year. This is probably a few hundred dollars lower than the actual value, but let’s say $2,000 for round numbers.
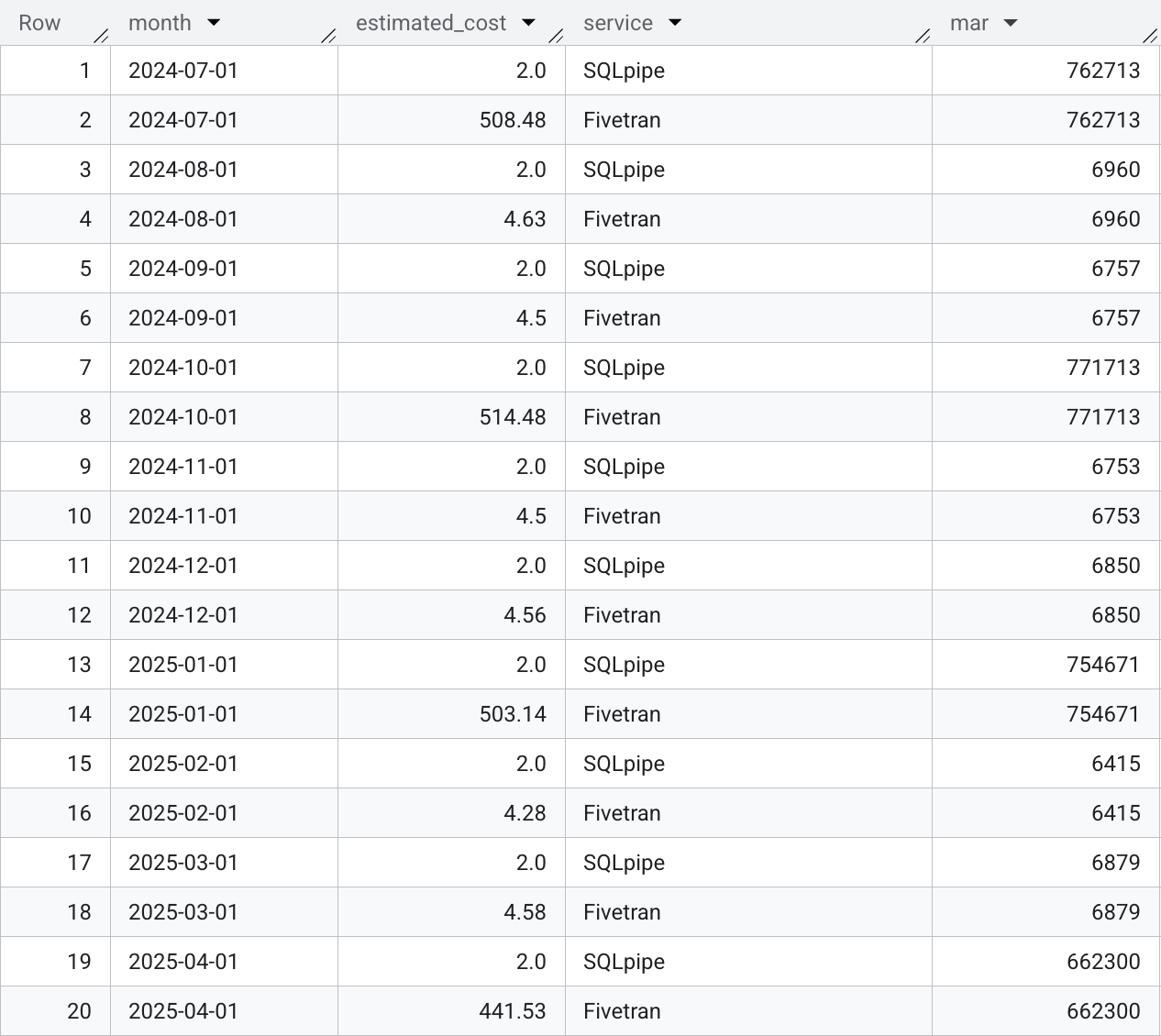
Fivetran charges according to monthly active rows, or MAR. To estimate MAR, I used BigQuery’s DATE_TRUNC function to sum all rows for each month, for each downloaded CSV. The query only looks at data that is older than 3 months, because some of the BIS’ datasets (especially the big ones, that actually cost money to transfer) are delayed by a few months.
The quarterly spikes have an MAR of around 750,000, maybe even a little higher. Below is the result of a query I used to calculate the MAR.
I believe the latest spike is smaller than the other 3 as the BIS hasn’t published a certain large dataset yet. Let’s say MAR is around 750,000 for those “spiky” months, again for round numbers.
If we plug this info into the Fivetran cost calculator, with the “Enterprise” plan selected, you get roughly $500 per month:
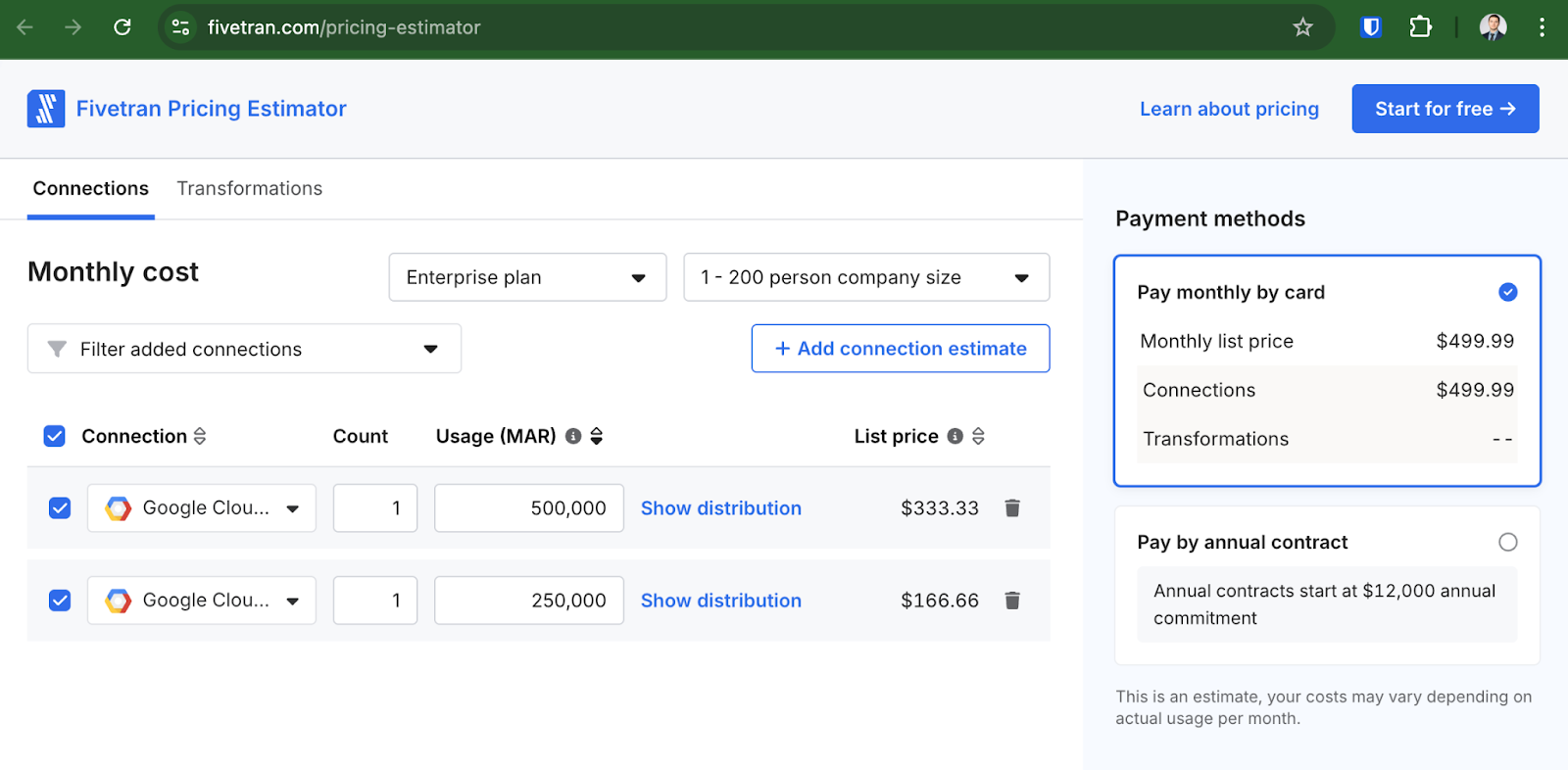
I split the dataset into 2 connectors with 500,000 and 250,000 MAR, because each dataset is considered a separate connection. According to Fivetran’s pricing page, you start getting a discount, per connector, at 500,000 MAR. I don’t believe any of the datasets I’m moving meet the 500,000 row threshold to get that discount, so I split them into two to reflect accurate price per row.
I won’t bother calculating the MAR of the smaller months, as they are trivial. So, for 4 main “spikes” costing $500 each, we get a price of around $2,000, yearly.
How much would this pipeline cost to develop on Fivetran?
Fivetran is a great tool. Really, I mean it! But it isn’t magic, and your team will need to spend time on the following tasks to set up an equivalent pipeline:
- Deploying up cloud resources
- IAM permissions
- Firewall rules
- Cloud storage buckets
- Developing orchestration to download the CSVs to the storage bucket, on a schedule.
- Downloading itself
- Alerting / retrying on failures
- Developing a transform within Fivetran to:
- Rename the CSV columns (the ones from the BIS are not great).
- Handle the commas within the column header names.
I estimate this work would take 2 days, assuming you already have Fivetran integrated into your environment and an orchestration tool ready to go. If you haven’t done these things yet, it could take a week or longer.
In the best case scenario, where it only takes 2 days, it would cost $1,200 to develop this pipeline. In the worst case, where you haven’t integrated Fivetran yet, and don’t have the correct orchestration and cloud resources set up, you’re looking at $10,000+.
Conclusion
I set up a data pipeline that saves a significant amount of money on Fivetran. If you’re interested in having my team help you save on your data pipelines please contact us! We only charge based on how much we save you.